Performance
Er zijn verschillende performance uitdagingen op de huidige versie van onze Linked Data bronnen. Deze tonen we hieronder.
Thema 1: Geo-Performance
Er zijn verschillende queries die een slechte geo-spatiële performance hebben. Deze kunnen we onderscheiden in twee problemen:
- slechte performance qua tijd.
- inaccurate resultaten.
We kijken eerst naar slechte performance in tijd. Wanneer een andere gemeente (i.e. geen caching) of een groter limiet wordt gekozen komen er meteen grote problemen naar boven.
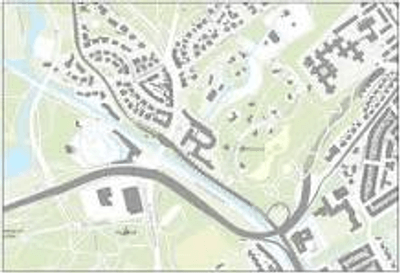
Wegen binnen een buurt
Inaccurate resultaten
Daarnaast zijn er verschillende geobevragingen die simpelweg incorrecte resultaten geven. Zie onder andere de onderstaande query.
Alle polygonen die een intersect hebben met een punt
Thema 2: Uitdagingen in de SPARQL Query Optimisation
De meeste administratieve queries weren als een trein, maar soms lijkt er om redelijk onverklaarbare redenen een query niet of heel slecht resultaten terug te geven. Dat kan soms komen door één extra attribuut of één extra relatie.
Administratieve Query over alle datasets vh Kadaster
Thema 3: Duplicate Results
In sommige gevallen geeft een SPARQL query onverwachte duplicate resultaten terug. Dit zorgt dus voor foutieve query resultaten. Een minimum working example is hieronder gegeven, wanneer een pand status voor één pand ervoor zorgt dat het aantal rijen verdubbeld wordt, ondanks dat dit één karakteristiek is van een pand.
Deze situatie viel op vanuit de KTH data story, maar zit waarschijnlijk in verschillende queries wel genesteld.
Duplicate resultaten van een bevraging
Thema 4: Federatie
Ook federatieve (geo-) bevragingen werken nog niet. Als er meer dan één service benaderd wordt gaat de performance door de grond.