
Introductie
In deze tutorial helpen we je om te kunnen exploreren door het data model van een gegeven dataset. Op deze manier kun je inzicht verkrijgen in de beschikbare data en de potentiële vragen die je met deze dataset zou kunnen exploreren.
Overzicht
Deze tutorial is de tweede in een reeks, bestaande uit de volgende delen:
- Stap 0 - Introductie
- Stap 1 - Exploreer het datamodel (dit artikel)
- Stap 2 - SPARQL bevragingstaal
- Stap 3 - Registratie vs. Knowledge Graph
- Stap 4 - Gebruik van eigen programmeertaal
Doel van deze module
Na deze module kun je aan je collega's uitleggen:
- Hoe je het data model van een dataset kunt exploreren.
- Hoe je de functionaliteit van een triple store gebruikt om inzichten in een dataset te krijgen.
Alle facetten van een dataset op één plek
Op de Kadaster developer pagina vindt je een overzicht van alle datasets die het Kadaster met linked data beschikbaar stelt. Daar vindt je per dataset verwijzingen conform Figuur 1.
Merk op dat voor iedere dataset de volgende verwijzingen zijn opgenomen:
- Een verwijzing naar de landing page van de dataset in de triple store. Hier vindt je metadata en changelogs voor de betreffende dataset.
- Een verwijzing naar het SPARQL endpoint waar een ontwikkelaar vragen over de data kan stellen.
- Een verwijzing naar de use cases die gebruik maken van deze dataset. Deze use cases geven een goede indruk van wat mogelijk is met de data.
- Een visueel overzicht van het data model van de dataset.
Voor de Kadaster Knowledge Graph lopen we door deze 4 opties heen.
Data model visueel inzichtelijk maken
Een van de 4 doorverwijzingen die in Figuur 1 getoond worden is de "Data Model" doorverwijzing. Voor de Kadaster Knowledge Graph is dat het volgende web adres: https://kadaster.wvr.io/kadaster-knowledge-graph Hier wordt een visualisatie van het data model getoond. Figuur 2 geeft hiervan een indruk.
Wij streven ernaar iedere dataset die wij beschikbaar stellen in een visuele interface beschikbaar te stellen. Hiervoor gebruiken we momenteel de tooling van Weaver. Neem bijvoorbeeld het data model van de Kadaster Knowledge Graph. Een screenshot vanuit de omgeving is hieronder toegevoegd.
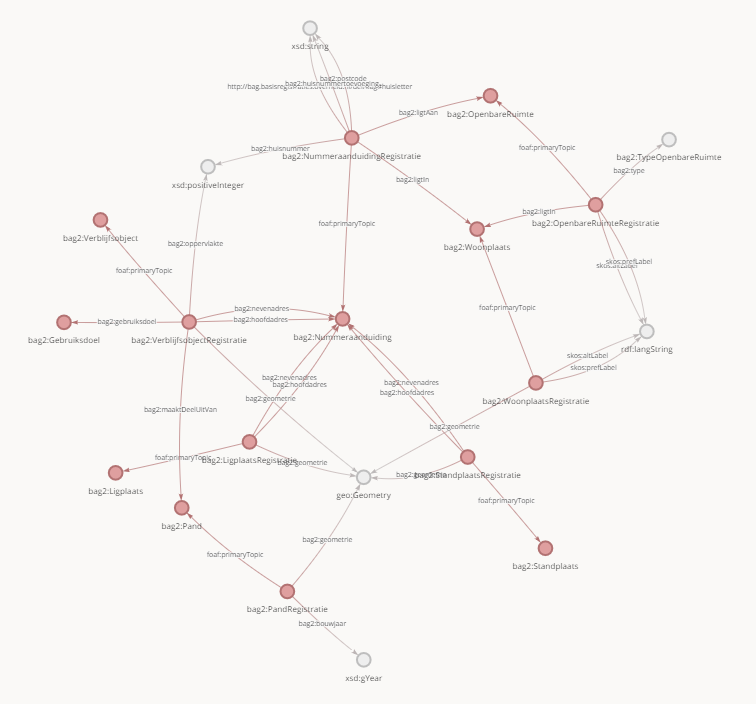
Je wordt binnen de omgeving standaard naar een view ("weergave") gebracht die door onze modelleurs - in samenwerking met de domeinexperts van de betroffen dataset - is klaargezet. In de praktijk is dit vaak een subset van alle beschikbare data in de dataset. Echter, om te voorkomen dat een gebruiker verdwaald raakt in een grote verbonden graaf aan objecten en relaties bieden we slechts deze subset als standaard view aan. Er kan echter meer data achter een object schuil gaan in de Weaver omgeving. Door te dubbelklikken op een object kunnen er additionele relaties en nodes verschijnen. De Weaver omgeving geeft vaak een eerste overzicht van de objecten en relaties die in de data zitten.
Uitdaging 1 Kenners van Kadastrale informatie weten dat er ook een object type Adresseerbaar Object bestaat. Kun jij deze vinden in de visualisatie omgeving voor het data model van de Kadaster Knowledge Graph?
De landing page van de dataset
Kadaster stelt haar linked datasets beschikbaar in een triple store. Een groot gedeelte van de Kadaster triple store is publiek toegankelijk zonder te hoeven inloggen. Hierdoor hebben ontwikkelaars toegang tot verschillende gereedschappen die het werken met linked data vergemakkelijken. De landing page van de Kadaster Knowledge Graph kan worden bezocht door op de volgende link te klikken: https://data.labs.kadaster.nl/dst/kkg Figuur 2 toont de pagina die je vervolgens aantreft.
Zoals je in Figuur 2 kunt zien bevat de pagina in de triple store metadata gegevens over de dataset. Een belangrijk onderdeel van de metadata is het versie nummer van de dataset. Omdat de data regelmatig door Kadaster wordt bijgewerkt wordt dit versie nummer regelmatig opgehoogd. In een nieuwe versie worden de gegevens inhoudelijk bijgewerkt, maar er kunnen ook fouten gerepareerd worden die aanwezig waren in een eerdere versie van de data. Een ander belangrijk metadata gegeven is de licentie waaronder de data wordt gepubliceerd. Deze licentie geeft aan wat de rechten en verantwoordelijkheden van de data publicist en de data gebruiker zijn.
Aan de linkerkant van het scherm zie je de volgende opties:
- Browser Hiermee kun je de gegevens in de Kadaster Knowledge Graph bekijken en naar gerelateerde gegevens navigeren.
- Table Hiermee kun je de gegevens in de Kadaster Knowledge Graph bekijken op het laagste 'triple' niveau. Dit toont de gegevens zoals ze in de triple store zijn opgeslagen. Door termen met de muis te slepen van en naar de "Subject" en "Object" kolommen is beperkte navigatie door de data mogelijk.
- SPARQL Hiermee kun je de Kadaster Knowledge Graph met SPARQL bevragen.
- Graphs Geeft een overzicht van de grafen die onderdeel uitmaken van de dataset. Grafen worden gebruikt om de dataset in verschillende onderdelen op te splitsen. Zo is het gebruikelijk om de metadata en het data model in een aparte graaf onder te brengen.
- Services Geeft een overzicht van de op dit moment over de data ontsloten diensten ('services').
- Assets Bevat bestanden die gerelateerd zijn aan deze dataset. Denk hierbij aan documentatie of presentatie (slide deck) bestanden.
- Insights Geeft een overzicht van de dataset op basis van interactieve visualisaties.
Browser
Een van de opties op de dataset landing page is de "Browser' optie. Je kunt deze browser bezoeken door op de volgende link te klikken: https://data.labs.kadaster.nl/dst/kkg/browser Figuur 3 geeft een indruk van hoe een gegeven en zijn eigenschappen binnen deze browser getoond wordt. Door op uitgaande waardes te klikken is het mogelijk om door de data te navigeren. Zoals onderaan in Figuur 3 getoond kun je naar de "Bronhouder" doorklikken. Naar navigatie naar voren is het ook mogelijk om navigatie 'terug' uit te voeren. Dit is inherent aan het graaf aspect van de data. Om de binnenkomende 'terug' links te volgen klik je op de verticale balk aan de linkerkant van de blauwe balk.
Inzichten ('Insights')
Een andere optie op de dataset landing page is de "Insights" optie. Je kunt deze inzichten bezoeken door op de volgende link te klikken: https://data.labs.kadaster.nl/dst/kkg/insights Er zijn verschillende inzichten beschikbaar. Figuur 4 geeft een voorbeeld van het "class frequency" inzicht.
In het "class frequency" inzicht wordt voor iedere graaf in de dataset getoond welke gegevens in die graaf aanwezig zijn. Instantiegegevens behoren altijd tot een specifieke klasse ('class'). Door op een klasse te klikken kun je vervolgens zien welke eigenschappen de instanties van die graaf hebben. Door over de balken te hoveren kun je bovendien het exacte aantal instanties per klasse en per klasse/eigenschap-combinatie inzien. Figuur 4 toont het "class frequency" overzicht voor de graaf die de gebouw gegevens uit de Basisregistratie Adressen en Gebouwen (BAG) bevat. Door een andere graaf te selecteren wordt het overzicht automatisch bijgewerkt.
Een ander inzicht is de "Class hierarchy". Hiervan wordt een voorbeeld in Figuur 5 getoond. Hiermee kan worden verkend welke klassen er gebruikt worden. Omdat klassen generieker en specifieker kunnen zijn vormen deze een hiërarchie. Door op de visuele elementen te klikken kan worden afgedaald in deze klasse hiërarchie.
Vervolg
Je kunt doorklikken naar de volgende of naar de vorige tutorial in deze reeks:
